The cart-pole balancing problem is a prototypical problem for reinforcement learning. A pole is attached to a cart with a rotating joint. An agent has to balance the pole by moving the cart left or right.
Most solutions in the internet seem to use reinforcement learning with complicated Keras model to solve this problem.
In this post, I will show that if you understand your system well enough, you don’t need any deep-learning schemes. In the case of cartpole balancing, all you need is some rudimentary knowledge of mechanics.
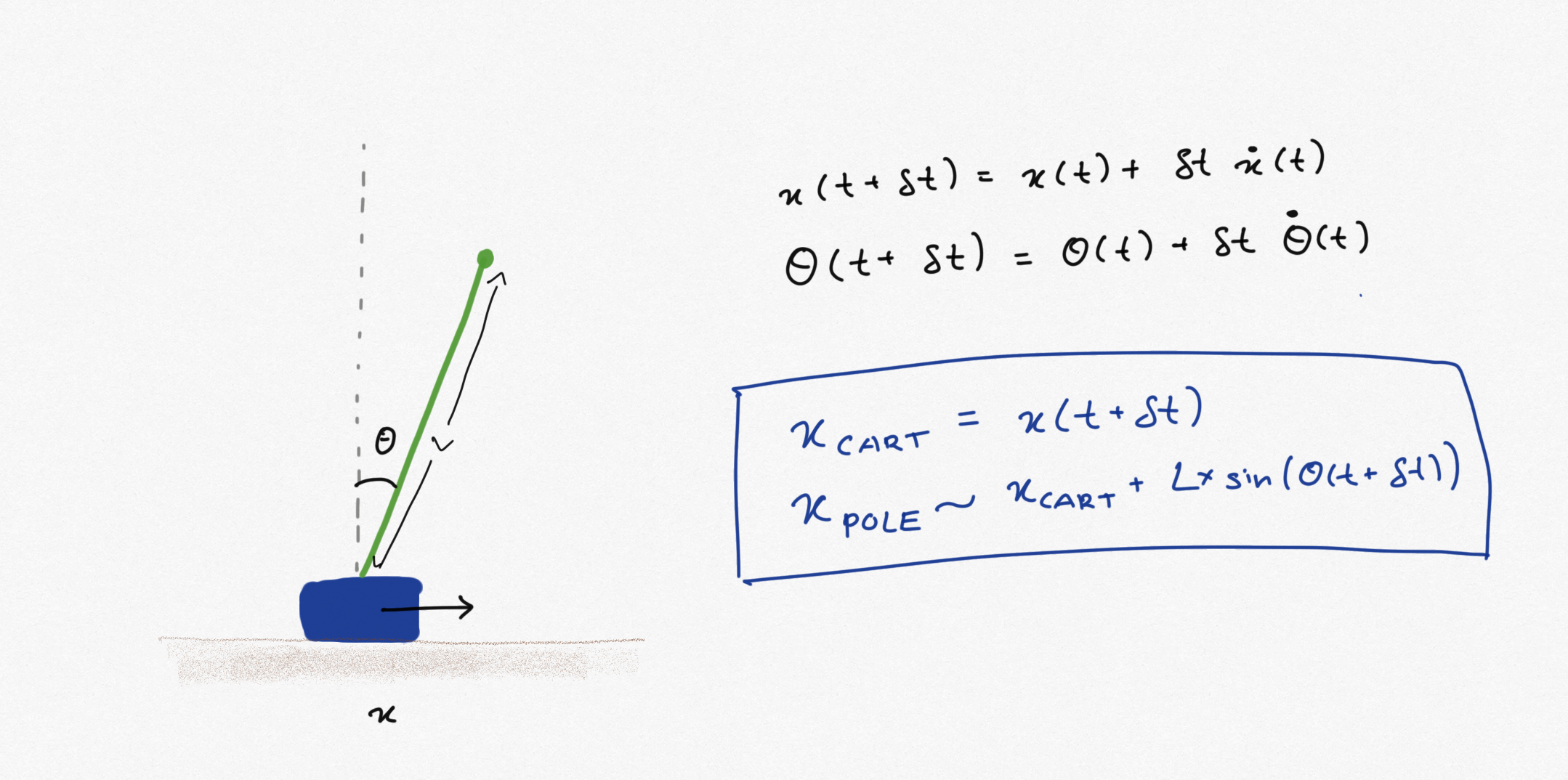
The state of the system at any time $t$ is given by $(x,v, \theta, \omega)$ with
- $x$ is the position of the cart.
- $v = \dot{x}$ is the velocity of the cart.
- $\theta$ is the angle of the pole relative to normal.
- $\omega = \dot{\theta}$ is the angular velocity of the pole.
With this, we can compute the positions of the cart and the pole at $t’$. The agent checks if the horizontal position of the cart is to the left of the horizontal position of the pole. If yes move the cart to the right, otherwise move the cart to the left.
The decision function looks like this:
def make_decision(x, v, theta, omega, L=1, dt=0.027):
predicted_theta = theta + omega*dt
predicted_x_cart = x + v*dt
predicted_x_tip_pole = predicted_x_cart + np.sin(predicted_theta)*L
return 0 if predicted_x_tip_pole < predicted_x_cart else 1
You need to know the time-step $\delta t$ and the length of the pole $L$. Through trial and errors, I saw that $\delta t \approx 0.027, L=1$ works great on my computer.
Let us use this decision function to balance the pole in OpenAI’s Gym environment.
import gym
import numpy as np
import matplotlib.pyplot as plt
env = gym.make("CartPole-v1")
MAX_SCORE = 500
n_episodes = 40
scores = []
for k in range(n_episodes):
env.reset()
step = 0
while True:
step += 1
env.render()
state = env.state
action = make_decision(*state)
_, _, terminal, _ = env.step(action)
if terminal or step >= MAX_SCORE:
break
scores.append(step)
There you go. You have balanced the cartpole without using any reinforcement learning.