It took me a very long time to understand what people mean when they say
vectorization(well at least for CPUs).Consider a simple function to multiply an array by a scalar
void vec_mult_scalar(int a[], int c) {
int i;
for(i=0; i<4096; i++){
a[i] *= c;
}
}
- A couple of things to note.
- First, I have assumed the array is of length 4096. This makes digging into the assembly instruction slightly easier.
- Second, the size of the array has to be kind of large. Vectorization doesn’t come cheap — for small arrays, the program might actually run faster without any vectorization.
The Naive Way of Multiplying an Array
- Let’s compile the code above without optimization (by using the compiler flag
-O0) and read the assembly output. gcc -O0 vec_mult_scalar.c -S && cat vec_mult_scalar.S- The assembly output looks like the following
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
xorl %eax, %eax
.p2align 4, 0x90
LBB0_1: ## =>This Inner Loop Header: Depth=1
movl (%rdi,%rax,4), %ecx
imull %esi, %ecx
movl %ecx, (%rdi,%rax,4)
incq %rax
cmpq $4096, %rax ## imm = 0x1000
jne LBB0_1
## %bb.2:
popq %rbp
retq
.cfi_endproc
## -- End function
Let’s try to parse the assembly instruction line by line. The main program only begins from the label LBB0_1. The stuff before is irrelevant to this dicussion. Before we dig into the assembly code above, a couple of things to remember:
- The first thing to know is that, when a function is called, the memory addresses of the arguments passed are stored in registers. The first argument gets stored in regsiter
%rdi, the second in%rsiand so on. To learn more about the exact order, I would recommend this page. - The register
%esiis the lower half of%rsi. While%rsiis a 64-bit register,%esiuses the lower 32-bits. More details here on how the r-registers and e-registers are related. - The command
movl A, Bmoves stuff from register A to register B. The suffixlsimply means that the register has the sizelong. - The other tricky thing is the notation
(A, B, C). It usually means: take the stuff inB, multiply that by stuff inCand add it toA. This is usually helpful in fetching array indices. For example, if the first element of an integer array $X$ is stored in the register%rdx,(%rdx, 1, 4)would get the memory address%rdx + 4which would be the array elementX[i], since integer arrays are stored in strides of 4 bytes. - Similarly,
D(A, B, C)means addDto the result of(A, B, C).
Now we are ready to understand the assembly output.
movl (%rdi,%rax,4), %ecxsimply moves%rdi + 4%raxto%ecx.%raxpresumably is holding the loop counteri. You need to multiply by 4 because each memory address stores a byte and an integer is 4 bytes long. This is similar to fetching the array itema[i].imull %esi, %ecxmultiplies the stuff we just stored in%ecxwith whatever is in%esi. The%esiregister is just the lower half of%rsi, so it is storing the 32-bit integer we passed as a scalar parameter.- After the multiplication, we return the multiplied stuff at
%ecxback to the array memorymovl %ecx, (%rdi,%rax,4). incq %raxjust increase the counter variable by 1.cmpq $4096, %raxcompares the counter with 4096.- If the counter is less than 4096, the line
jne LBB0_1returns it back to the top of the loop.
The loop is very dumb. It moves an element of array to a temporary calculator, multiplies the data in calculator, and returns the new data back to the memory where it came from. This process is repeated for each element in the array one at a time.
Vectorized Compilation
Now let’s turn on vectorization and see what the assembly code looks like in this case. gcc -O3 vectorization.c -S && cat vectorization.s gives the following assembly code.
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movd %esi, %xmm0
pshufd $0, %xmm0, %xmm0
xorl %eax, %eax
.p2align 4, 0x90
LBB0_1: ## =>This Inner Loop Header: Depth=1
movdqu (%rdi,%rax,4), %xmm1
movdqu 16(%rdi,%rax,4), %xmm2
movdqu 32(%rdi,%rax,4), %xmm3
movdqu 48(%rdi,%rax,4), %xmm4
pmulld %xmm0, %xmm1
pmulld %xmm0, %xmm2
movdqu %xmm1, (%rdi,%rax,4)
movdqu %xmm2, 16(%rdi,%rax,4)
pmulld %xmm0, %xmm3
pmulld %xmm0, %xmm4
movdqu %xmm3, 32(%rdi,%rax,4)
movdqu %xmm4, 48(%rdi,%rax,4)
addq $16, %rax
cmpq $4096, %rax ## imm = 0x1000
jne LBB0_1
## %bb.2:
popq %rbp
retq
This certainly looks a bit more involved than before. The most important change to note is the presence of registers like %xmm0 and new commands like movdqu or pmulld.
The XMM registers are 128 bit registers. They can hold four 32-bit integers. And it can apply operations parallely across the entire register. What this means for us is that if we can pack the XMM register with four integers, we can multiply all of them at once. I borrowed the following picture from Intel’s Tutorial on Vectorization
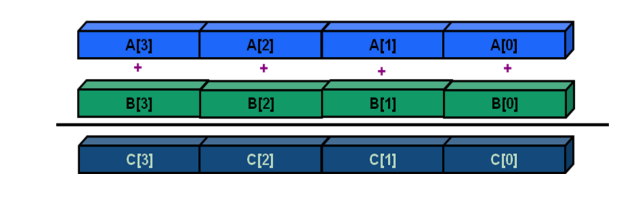
Let’s dig into the assembly code
- Just before the main
LBB0_1section begins, we see an instructionmovd %esi, %xmm0. It just moves the scalar parametercto the%xmm0register. A few weird things here. The scalar is really a 32-bit integer.%xmm0is a 128-bit register. Andmovdis treating the data being moved as a double (64 bit). For now, we can sweep the subtleties under the rug. At this point the register%xmm0looks like the following
32 32 32 32 bits
----------------------------------------------------
| | | c
----------------------------------------------------
- The command that follows immediately
pshufd $0, %xmm0, %xmm0is kind of complicated. This technical reference is also kind of opaque. All we need to know is that after this operation, the%xmm0register looks like the following
32 32 32 32 bits
----------------------------------------------------
c | c | c | c
----------------------------------------------------
- Entering the loop, the sequence of
movstatementsmovdqu (%rdi, %rax,4), %xmm1; movdqu 16(%rdi,%rax,4), %xmm4; ...movdqu 48(%rdi,%rax,4), %xmm4moves blocks of four integers (128 bits) from the array to the XMM register.movdqujust means move double quadwords (just another way of saying 128 bits). The block beginning from(%rdi, %rax,4)gets stored in%xmm1. Since%xmm1has 128 bits, this should fit four integers. The block beginning from16(%rdi, %rax,4)or rather(%rdi, %rax,4) + 16goes to%xmm1. The 16 (with is just the length, in bytes, of four integers) is important because the data between(%rdi, %rax,4) + 0and(%rdi, %rax,4) + 15is stored in%xmm1already. - The operation
pmulld %xmm0, %xmm1just multiplies the block of four integers packed in%xmm1with the scalar value packed in the register%xmm0. - After the multiplication, the multiplied integers packed in the XMM registers are dragged back to the array memory location.
- For some reason, the compiler uses four XMM registers. It first multiplies two XMM registers in a row, moves the data, and then multiplies the remaining two registers. I do not fully understand why it doesn’t multiply all four in a row.
- Finally, once all numbers are multiplied, the loop exits.
Takeaways
- Vectorization is achieved by using these humongous XMM registers that can do parallel operations.
- The compiler can optimize most loops – as long as the loops are simple enough.
- For auto-vectorization to work, the loop counters must be invariant (the loop exit condition should not change once the loop starts). There shouldn’t be complicated control-flow or break/continue statements inside the loop.
- When manipulating arrays in a loop, you should be careful about data dependency. For example, if the loop contains assignments like
a[i] += a[i-1], vectorization will not work.